Most of our existing customers and leads rely on some form of data subscriptions around Indian private companies’ financial data. Data has long become an important input to businesses (investors and corporates) to make decisions. Quality and quantity of the data from providers have to ensure before any other subscription purchase decision is made.
The concept of data quality, fill rate, and data coverage as key metrics for evaluating data subscriptions is undermined among buyers because they do not get this information from other vendors to compare.
In this blog post, we will openly talk about how as a buyer you can go about evaluating on operating metrics of any data subscriptions you are potentially getting into.
Data Quality
You can understand quality in its broadest terms, where you rely on the data that is coming as is without having to recheck or do further sanity/verifications to make decisions. This will mean that the data is already accurate at the point of consumption all the way back to its original source.
In our business around India’s private market intelligence, data quality simply means will I get the complete picture of a company, investment, investor, or loan when I look for it. Will it be valid when I use to make say an investment decision? and Can I compare to others and make business judgments? Will it be available when I need it without gaps in time series or missing large comparables?
So validity, consistency, and availability are key considerations when you make a call on who can potentially be your next vendor.
In many business use cases, the accuracy need not be 100%. In fact, many of the crawled or socially generated data will have some amount of noise that can be acceptable. For example, it is not necessary to make a marketing campaign decision only after having full, accurate, or granular information about what will work in order to launch. In some cases, customers might decide not to pay a premium for accuracy-guaranteed data.
How PrivateCircle Research delivers data quality?
The first thing about data quality and accuracy is knowing the source. On PrivateCircle if private company data is being shown on a screener, the user has the option to go back to the actual filing where the data appeared and verify for herself.
The second thing to ensure data accuracy is having consistent processes and rules. For example in most PrivateCircle calculations when the basis is not given (by the filing or data) then any assumption made is given explicitly. If there are changes to this assumption, the user can flag or modify calculations at his end before making material decisions. Processes are a necessity when we deal with multiple forms, filings, and sources and we have dedicated tech that augments any human interventions to handle exceptions and brings it as part of the tech to have it handled perpetually.
You will be surprised to know our onboarding processes are mostly around what is standard and what are the known exceptions. This way keeping high accuracy levels becomes part of the culture and habit.
Fill Rate
Fill rate is the rate at which data points are filled in compared to a larger complete data set or the universe. Usually, it is measured over time and in almost all cases the universe is also growing. So simply trending fills as compared to the universe will help you measure if you can rely on the vendor. Fill rates can also be tracked at individual column level, especially when data availability is not consistent. If both columns and rows fill rate is low, end users are potentially looking at a sparse matrix of data. Surely no buyer wants to be stuck with slowly filling data vendors when new data is growing much faster, as these significantly affect decisions made in the now.
How PrivateCircle Research ensures a decent fill rate?
We prefer the moving averages on the fill rate of companies we profile as well as how the universe of all companies incorporated in India to showcase. This is useful because when companies incorporate at a high rate like in the past 2 years and when the actual fill rate of data is remaining stagnant is an issue. This is critical if you are looking to make decisions based on available data. Our users request more companies and our own automation makes sure deals, companies, and corresponding cross references with investors/lenders are ticking up to keep our data
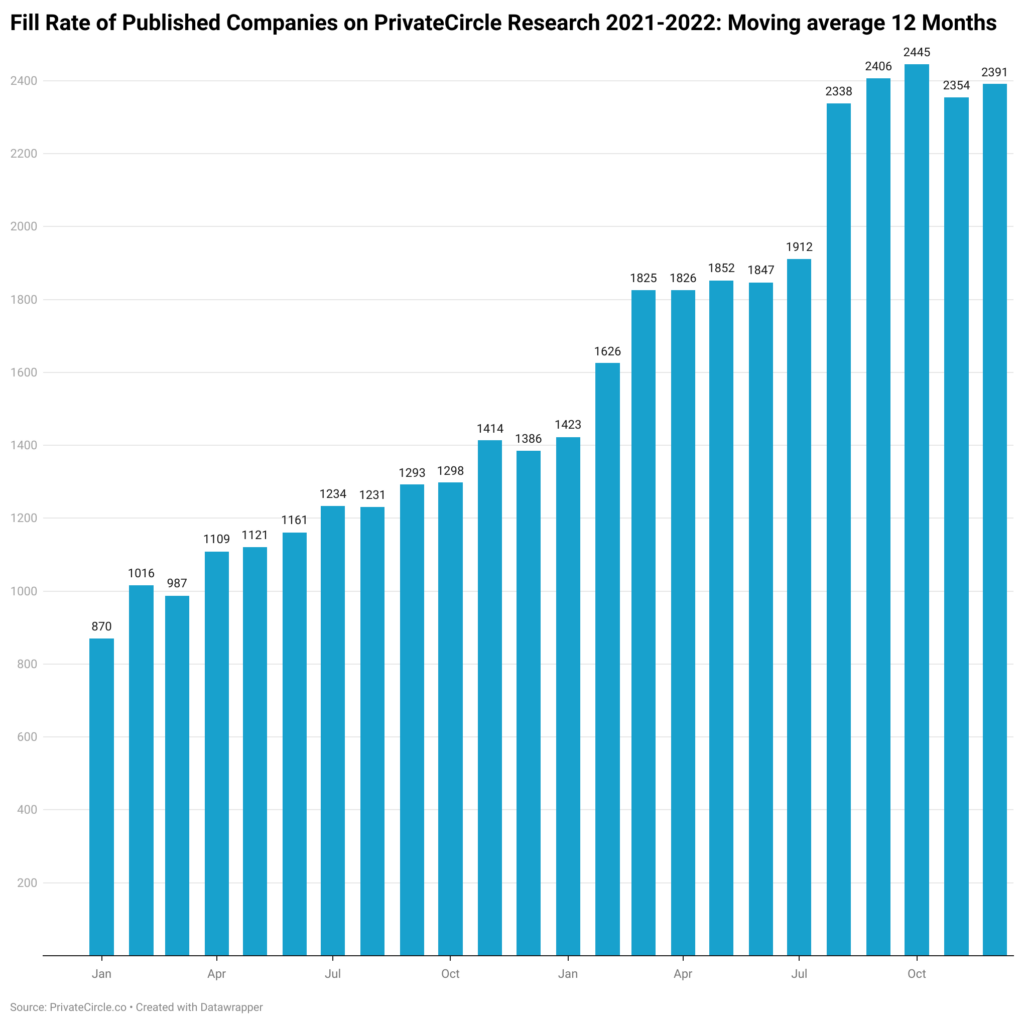
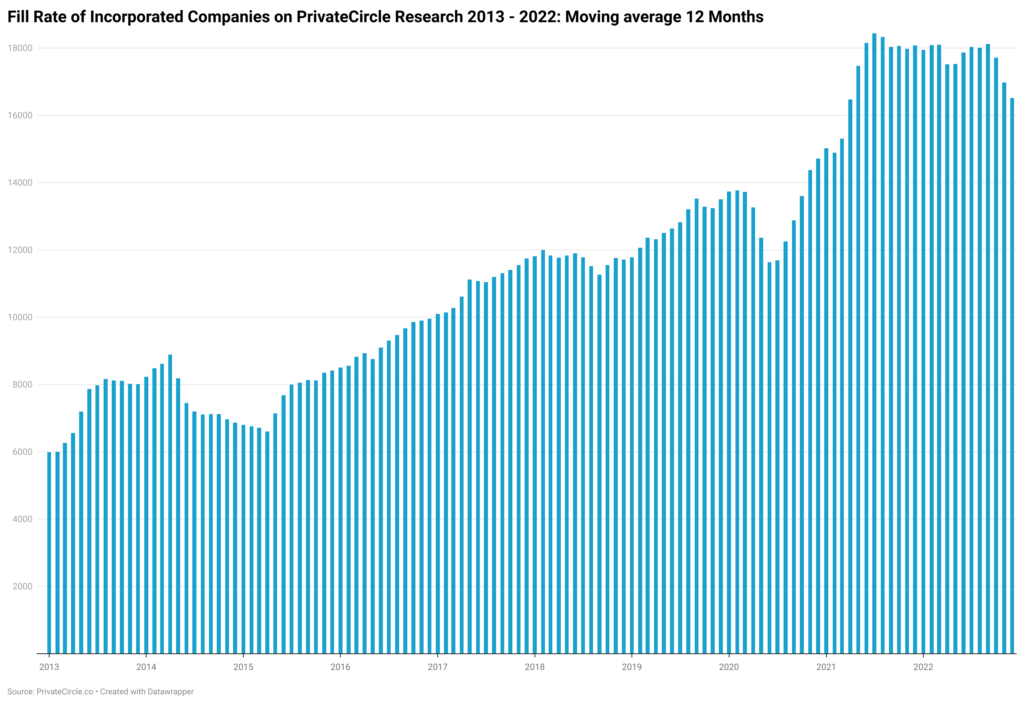
Data Coverage
Data coverage is the percentage of relevant data that a given data source offers. This metric can be used to assess the comprehensiveness and completeness of a dataset. In data vendors who rely on crawl or other sources, if there is a completely new source leaves a large gap in the data. Coverage can be visualized both horizontally as well as vertically. Horizontal coverage can in turn be seen over time or in segments of data that are most relevant to the users. Whereas vertical coverage is within a particular dataset how deep can the user go?
How is the coverage on PrivateCircle?
In the PrivateCircle case, we add new sources regularly. These sources stabilize over time allowing us to make sure when data is coming in it is available in its full feature set to the users depending on their needs. For example, every year when companies file returns, their historicals are retained allowing for a more complete view of the company. Similarly with better coverage, comparing between locations, sectors, investor types or other dimensions becomes more reliable when you use PrivateCircle Research.
We are not even speaking about big data here when evaluating data providers. Financial data are mostly tabular small data, even that has a huge impact on how businesses operate especially when the data is accurate, complete, and filled at a decent pace. When evaluating data or intelligence providers it may be worthwhile asking vendors to disclose some of these metrics before making the call.